Deep Research Pipeline
The isolated 6-step pipeline that produces structured market reports
Deep research is a specialized pipeline that runs alongside (but
separate from) the main agent loop. Where the agent loop is
conversational and permission-gated, the deep research pipeline is
a six-step state machine that produces a single structured report.
Implementation lives in
apps/agent/src/deep-research/pipeline.ts.
Why a separate pipeline instead of letting the agent loop iterate? Multi-source research needs parallel data gathering (fan-out then merge), LLM-as-judge quality checks, and retry logic that doesn't fit the conversational
plan → call → observecadence. A dedicated pipeline also keeps research output deterministic + citable, which a conversational loop can't guarantee.
See this in use: Features → Deep Research covers the user-facing side with example report output.
When to use it
Use the pipeline when the goal is a written artifact rather than a chat answer:
- Long-form market analysis on a specific asset or theme.
- Multi-source synthesis that needs to cite each claim.
- Scheduled research runs where you want an artifact you can reference later by id.
For quick conversational questions ("what's the price of BTC", "should I long here"), use the agent loop. The deep research pipeline has higher latency, a fixed tool budget, and no memory of the ongoing conversation.
The six steps
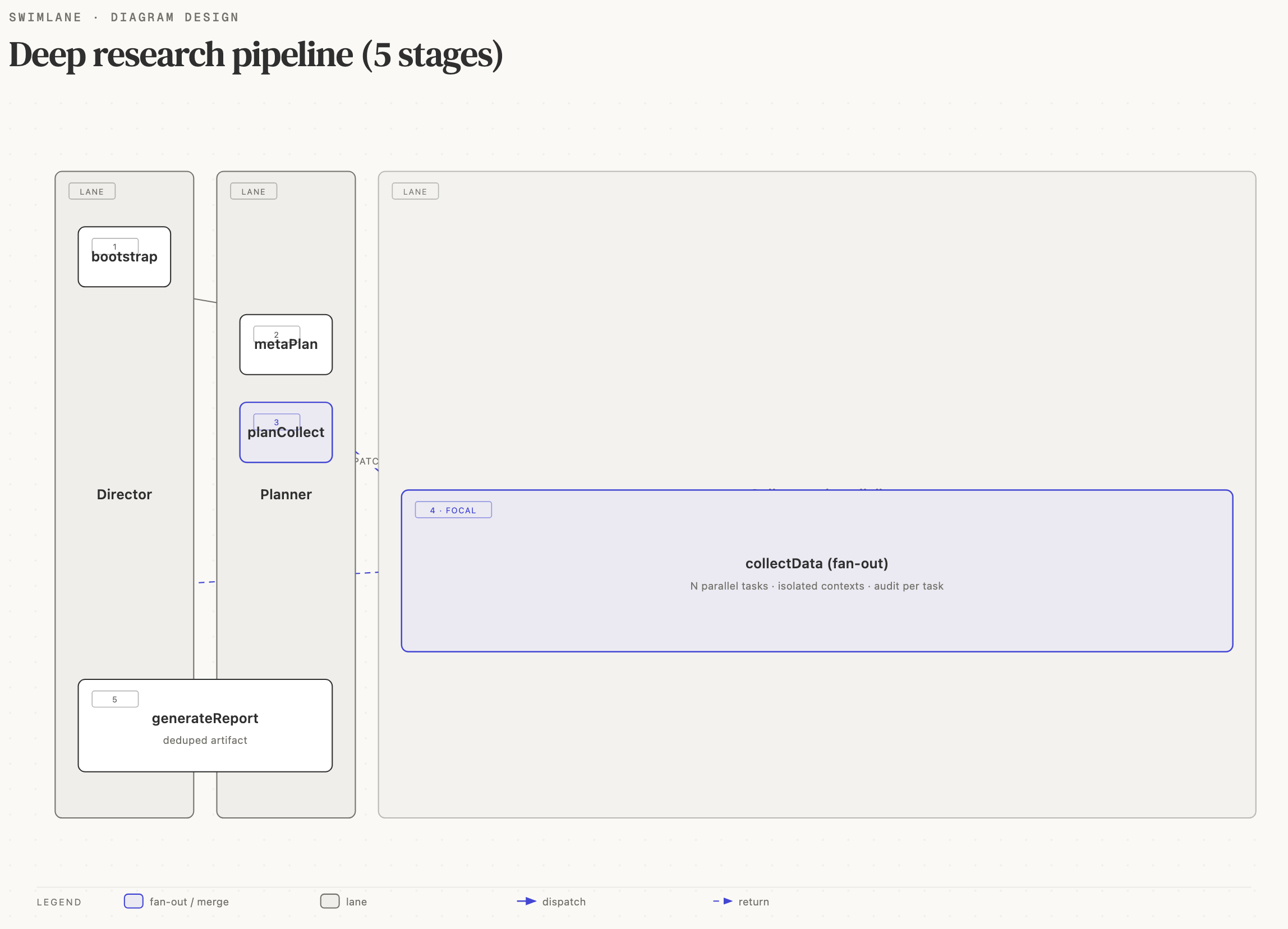
Each step is a single LLM call except collectData, which runs a
sub-agent loop against the tool registry for every goal.
Isolation from the main agent loop
The pipeline is intentionally isolated:
- It does not see the chat's conversation history.
- It does not consume the skill system's activation state.
- It builds its own narrow tool subset for data collection rather than using the currently active skills.
- It does not trigger learnings (
review-enginenever runs on pipeline turns).
This isolation buys two things: determinism (every research run starts from the same state) and cost control (a chat mid-long session can't bleed its history into research cost).
Modes
interface ResearchRequest {
chatId: string;
userMessage: string;
mode?: "light" | "heavy";
language?: string;
}light(default). 2 parallel collection goals, smaller max iterations, single-pass report. Typical latency: 30–60 seconds.heavy. 4 parallel collection goals, larger iteration budget, more thorough synthesis. Typical latency: 2–5 minutes.
Pick light for scheduled/cron research and heavy when the user
explicitly asks for a thorough report.
Scenarios
Reports are organized around scenarios: pre-defined angles
like "bullish case," "bearish case," "base case," "regulatory
risk," "macro backdrop." The metaPlan step picks 1–4 from the
catalog in
apps/agent/src/deep-research/scenarios.ts
based on the topic.
Scenario selection is load-bearing for report quality: a BTC research report without a "macro" scenario often misses the most important context, and one without "bearish case" produces confirmation bias. The catalog is kept deliberately small so the LLM's scenario picker is reliable.
Output artifact
The result is stored in ArtifactStore as a report artifact:
interface ResearchResult {
report_id: string;
status: "completed" | "error" | "waiting_for_input";
title: string | null;
research_topic: string | null;
scenarios: string[];
summary: string | null;
key_findings: string[];
report_markdown: string | null;
error?: string;
tokens: { input: number; output: number };
}The main agent can quote a finished report back to the user via
the report://{id} URI scheme. This is how you compose research
with conversation: the user asks for research, gets a
report_id, then asks follow-up questions in the chat that
reference the report.
Report bodies are markdown. They include scenario headers, inline
citations (via [text](url)), and a "Key Findings" bullet list
the summarize step produces.
Running it
From the REPL
The main agent activates the deep-research domain skill and
calls the deep_research_run tool:
> write me a report on ETH staking yields this quarter
assistant: [activates deep-research skill]
assistant: [calls deep_research_run with mode=heavy]
assistant: ✓ report_id: r_abc123 — here's the summary…From the CLI subcommand
Bypass the REPL entirely:
minara research "BTC ETF flows this quarter"
minara research "macro risks for Solana" --mode heavySee Subcommands → minara research for the full flag list.
From an HTTP request
curl -X POST http://localhost:8080/research \
-H 'content-type: application/json' \
-d '{"topic": "BTC ETF flows", "mode": "light"}'See API → /research for the request and response schemas.
Cost and observability
Each step records {provider, model, tokens} in the audit log
under source: "deep_research". The tokens field on
ResearchResult is a best-effort aggregate for quick cost
accounting. For precise cost attribution, query the audit log:
SELECT model, SUM(input_tokens), SUM(output_tokens), COUNT(*)
FROM audit
WHERE source = 'deep_research'
AND trace_id = ?
GROUP BY model;The deep research pipeline is the biggest single LLM cost in most Minara deployments. If your bill is unexpectedly high, this is usually the first query to run.
Extending the pipeline
The pipeline is deliberately short (~700 lines in pipeline.ts).
Common extensions:
- Add a scenario: append to the catalog in
scenarios.ts. The meta-plan prompt reads the catalog at runtime, so no prompt changes are needed. - Change collection concurrency: set
collectConcurrencyinPipelineConfig. Default 4, matching the v1 ceiling. - Change max iterations per goal: set
collectMaxIterations. Default 8. This is the LLM-turn budget for each data-collection sub-agent. - Add a post-processing step: append another method to the
pipeline class and call it between
summarizeand the return. Do not inline logic into an existing step; the step boundaries are what make the pipeline debuggable.
Do not wire the pipeline into the main agent loop's history. The isolation is a feature; breaking it will let chat cost leak into research cost.
What NOT to put in research
- Real-time price-dependent decisions. The pipeline takes minutes; prices move. Use the agent loop for anything that depends on current execution conditions.
- Fund-moving tool calls. Data collection uses a narrow tool subset that excludes every fund-moving tool. The pipeline refuses to run if its tool subset accidentally includes one.
- Private user context. The pipeline does not read the user's
wallet balances or history. It speaks to public market data.
If a report should account for the user's specific position,
surface the position in the user message at
bootstraptime; the pipeline will thread it into subsequent steps.