Learning System
How the agent gets better at recurring tasks over time
Minara Agent ships a learning loop that records successful tool sequences and surfaces them as suggestions on future turns. Unlike model fine-tuning, this is all SQLite rows. No training job, no model update, no offline pipeline. This page explains the pieces and how they cooperate with the skill system.
What "learning" means here. In Minara, "learning" is not fine-tuning or weight updates. The model stays the same. What changes is what the agent retrieves from SQLite before each turn: a library of
{tool_name, args}sequences that worked, free-text guidance notes, and structured methodologies. A new turn that looks like a past successful one gets the past sequence as a suggestion. That's it. The design trades sophistication for auditability: every "learned" behavior is a row you can read, edit, or delete, and no behavior persists that the operator can't inspect.
See this in use: Features → Self-Improving covers the user-facing surface — how you nudge the agent into saving a lesson and how those lessons show up in later sessions.
For the parallel decision-reflection loop (two-stage LLM classification of whether a specific skill call was right or wrong, scoped per role), see Role Memory. That system runs alongside this one and answers a different question: not "how did I succeed" but "was this specific decision correct, and why".
What gets learned
Three distinct artifacts live in the learnings table (and its
sister tables under apps/agent/src/learning/):
- Tool sequences. An ordered list of
{tool_name, args}pairs the agent successfully ran to accomplish a task. Recorded when the agent explicitly callsskill_learnat the end of a turn. - Guidance notes. Short free-text blurbs like "for Polymarket
prices, use
web_extracton the specific market URL. The API rate-limits at 10 rpm." These ride alongside tool sequences. - Methodologies. Structured multi-step plans with success
criteria, stored by
learning/structured-methodology.ts. Used for deep-research workflows where a plain tool sequence isn't expressive enough.
The feedback loop
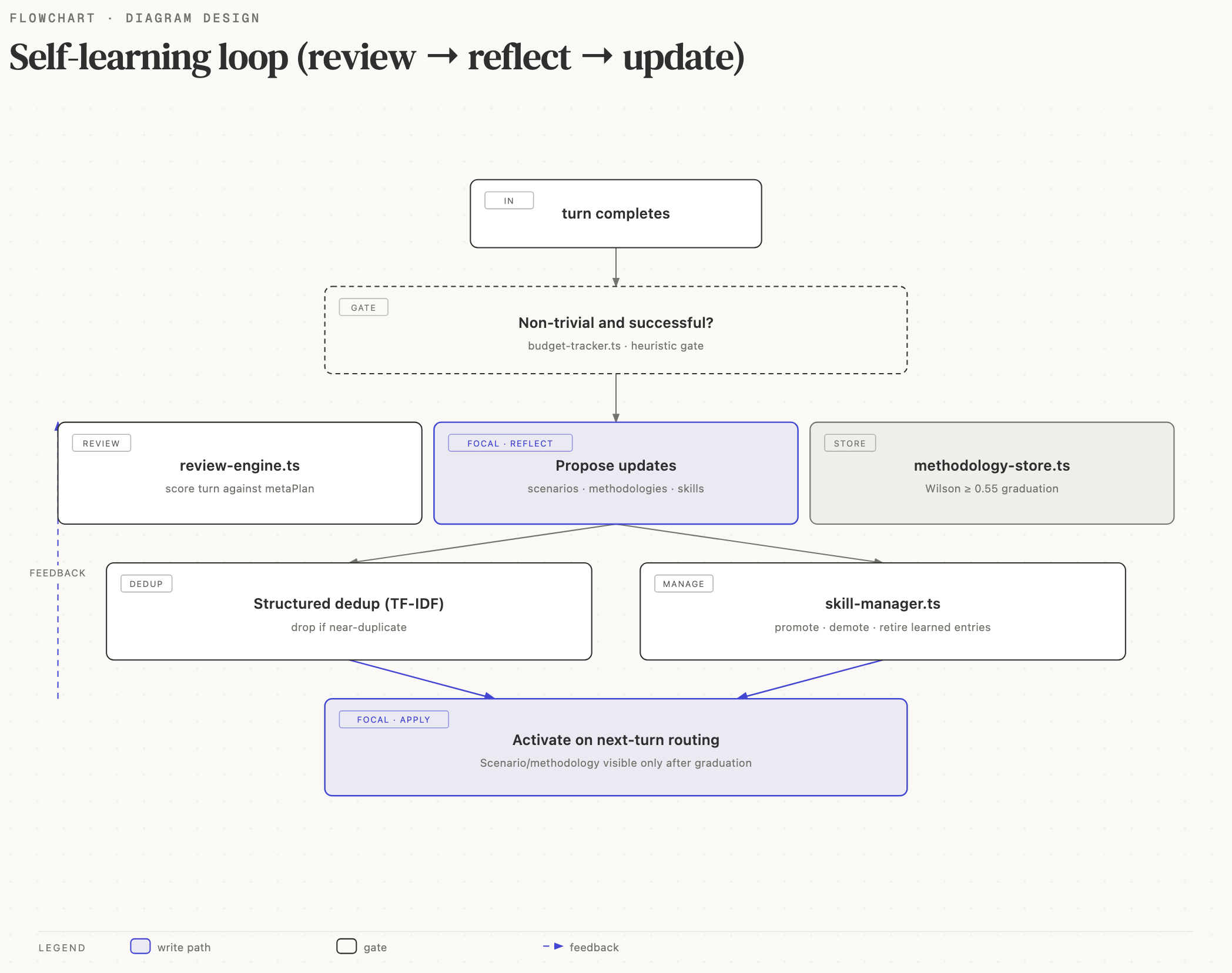
review-engine
learning/review-engine.ts
is a lightweight LLM pass that runs at the end of a turn (via
review-engine-hook.ts installed in app.ts). It:
- Inspects the turn's tool call sequence.
- Filters out turns with fewer than N calls or obvious failures.
- Calls a cheap model (the fast tier) with a structured prompt asking "was this task completed? how novel? how reusable?"
- Emits a
ReviewResultwith{score, summary, suggested_trigger, suggested_tool_sequence}.
If the score passes a threshold, the result is handed to the skill manager.
skill-manager
learning/skill-manager.ts
owns the learnings table. On a qualifying review it writes:
{
id: uuid,
name: "hyperliquid_open_long_with_tp_sl",
trigger: "open long on hyperliquid with tp/sl",
tool_sequence: [...],
guidance: "always set TP before SL; Hyperliquid's 'reduce_only' flag...",
created_at,
success_count: 1,
failure_count: 0,
last_used_at: null,
}It also deduplicates: if a near-identical trigger already exists
(cosine similarity via
learning/similarity.ts
and TF-IDF via
learning/tfidf.ts), the new
observation updates the existing row's counters rather than
creating a duplicate.
evaluation-loop
learning/evaluation-loop.ts
runs at the start of every turn. It:
- Builds a TF-IDF query from the user message plus router context.
- Scores every learning against the query.
- Returns the top K matches (default 3).
- Hands them to the prompt builder, which appends them to the
system prompt as a
<learnings>block with the trigger, tool sequence summary, and guidance text.
The LLM is free to adopt or ignore the suggestion. Either choice
updates the learning's counters. Adoption that led to a successful
turn increments success_count; ignored learnings slowly decay.
Methodologies: structured plans
Deep-research turns produce a different artifact: a methodology. Where a tool sequence is a flat list, a methodology is a tree of phases with success criteria:
{
id, name,
phases: [
{name: "Gather", criteria: [...], tools_used: [...]},
{name: "Synthesize", criteria: [...], depends_on: ["Gather"]},
{name: "Verify", criteria: [...], depends_on: ["Synthesize"]},
],
asset_class: "crypto_alt",
...
}The store is
learning/methodology-store.ts
and the deep-research skill reads from it to seed multi-phase
research plans. Methodologies are a finer-grained learning artifact
for tasks where "what tools to call" is less interesting than "what
intermediate evidence to gather."
Why this differs from a vector memory
A simple vector memory would just store facts and recall them. The learning system stores procedures: "how to accomplish this class of task." It then surfaces them as executable suggestions. The distinction matters:
- Vector memory answers "what do I know about BTC?"
- Learning system answers "how do I usually handle a request to long BTC on Hyperliquid with TP/SL?"
The two are complementary, and the agent uses both. Memory lookups
happen in the skill layer via memory_search; learning lookups
happen in the agent loop before the first LLM call, as part of
prompt assembly.
Safety properties
Learnings are suggestions. They are never mandates. Specifically:
- A learning can never bypass the permission tier hook. A
suggested
tool_sequencethat contains a tier-4 tool is still blocked when the turn source doesn't permit it. - A learning can never bypass the L3 risk gate. If the
suggested sequence requires activating a
requires_user_confirmationskill, the normal confirmation flow applies. - A learning cannot store secrets. The
argsrecorded in a tool sequence go through the same redactor as the audit log. - Failed turns never become learnings. The review engine filters them out before the skill manager ever sees them.
Inspecting and curating
# Top learnings by success rate
sqlite3 $dataDir/minara.db \
"SELECT name, success_count, failure_count
FROM learnings
ORDER BY success_count - failure_count DESC LIMIT 20;"
# Recently used
sqlite3 $dataDir/minara.db \
"SELECT name, last_used_at FROM learnings
WHERE last_used_at IS NOT NULL
ORDER BY last_used_at DESC LIMIT 10;"
# Delete a bad learning
sqlite3 $dataDir/minara.db "DELETE FROM learnings WHERE id = '...'"There is no "demote" operation. If a learning is misleading, delete it. The agent will re-derive it if it was genuinely useful.
Configuration
Relevant env vars (see env-vars):
MINARA_LEARNING_ENABLEDis the master switch (defaulttrue).MINARA_LEARNING_MIN_CALLSis the minimum tool calls per turn before a review is considered (default3).MINARA_LEARNING_SCORE_THRESHOLDis the review score required to write a learning (0–10, default7).MINARA_LEARNING_TOP_Kis how many learnings to surface per turn (default3).
Turning MINARA_LEARNING_ENABLED=false completely disables the
loop: no writes, no suggestions, no review passes. The agent still
works; it just doesn't get faster over time.
Budget tracking
Every LLM call the learning system makes goes through
learning/budget-tracker.ts,
which enforces hard caps per category and per window.
This was added after a review warned that the two-stage judge
pass plus post-hoc probes could easily 10× LLM costs if a bug
or adversarial prompt produced runaway reflection. A hard
budget is the circuit breaker.
Four categories, each with independent daily + monthly caps:
| Category | Purpose |
|---|---|
learning | Review engine, methodology extraction, role reflection, skill learning |
agent | The main agent-loop turns themselves |
workflow | Workflow and autopilot turns |
experiment | Offline experiments, backtests, A/B tests — never touched in prod |
State is persisted to the llm_usage SQLite table:
CREATE TABLE llm_usage (
id INTEGER PRIMARY KEY AUTOINCREMENT,
category TEXT NOT NULL,
task TEXT NOT NULL,
model TEXT NOT NULL,
input_tokens INTEGER NOT NULL,
output_tokens INTEGER NOT NULL,
cost_usd REAL NOT NULL,
date TEXT NOT NULL,
ts TEXT NOT NULL
);On every LLM call the tracker:
- Projects the estimated cost against the current daily and monthly totals for the category.
- If the projected total would exceed the hard cap, throws
BudgetExceededErrorbefore the call fires. - If the projected total crosses a soft threshold (below hard cap), emits a warn-level structured log but allows the call.
- After the call completes, records the real token counts and
cost back into
llm_usage.
Budgets survive restarts because the state lives in SQLite. There's no in-memory counter to reset.
To inspect spend without running the agent:
sqlite3 $dataDir/minara.db \
"SELECT category, SUM(cost_usd) FROM llm_usage
WHERE date = date('now') GROUP BY 1;"The /budget REPL command exposes the same view interactively.
Methodology store
learning/methodology-store.ts
is the Phase 2 heart: the agent learns which analysis
methods produce profitable signals for which asset classes,
and retrieves them for future similar analysis.
Each methodology is stored with:
| Field | Meaning |
|---|---|
id | UUID |
asset_class | One of the known asset classes (major_crypto, layer_1, defi_blue_chip, meme_coin, stock, …) |
methodology | Free-form text description of the method |
evidence | Supporting evidence text |
confidence | Wilson lower-bound confidence score in [0, 1] |
times_used | Successful applications |
times_correct | Applications that passed outcome verification |
quarantine | 1 until the method passes N successful uses without anomaly detection |
dedup_key | Hash of structured fields for O(1) semantic dedup |
structured_json | Normalized StructuredMethodology (see below) |
Quarantine and injection defense
New methodologies start quarantined with confidence: 0.1.
They are not injected into prompts until they pass enough
successful uses. Anomaly detection runs against the methodology
text on every write via
scanMethodologyForInjection
to catch prompt-injection patterns before they land in the
store.
Confidence bumping
Every time a methodology is applied and the outcome is verified:
- Success: increment
times_correctandtimes_used, recomputeconfidenceas the Wilson lower-bound on the binomial (which penalizes small samples). - Failure: increment only
times_used, recompute confidence. Methods that fail often see their confidence drop below the injection threshold. - Graduation: once
confidence >= INJECTION_THRESHOLDandtimes_used >= MIN_USES, flipquarantine = 0. The method is now eligible for prompt injection.
Wilson lower-bound beats raw times_correct / times_used
because it doesn't let a 1-in-1 lucky hit outweigh a 15-in-30
consistent winner.
Institution mode: the reflection ladder
Institution Mode is the heaviest writer into the methodology store. Each run convenes several LLM roles (analysts, a bull/bear debate, a risk committee, a portfolio manager) and records their decisions. Those decisions feed a delayed reflection loop that scores each call against what actually happened and graduates lessons back into the store described above.
Why decision roles use forced structured tool-use
Every decision-producing role emits a tool call that has to match a Zod
schema (AnalystReportSchema, TraderProposalSchema,
PortfolioDecisionSchema, and so on). Free-form prose alongside the call
is discarded. Two reasons, both about the reflection loop:
- Determinism. Reflection scoring compares the same fields across runs. A rescue-parse of free text drifts under model upgrades; a fixed schema does not.
- Comparability. A
Buyat confidence 0.71 today is only directly comparable to aBuyat 0.62 last week if the schema is constant.
When INSTITUTION_LEARNING_ENABLED=1, the capture hook writes
institution_runs (run metadata) and institution_role_outputs (each
role's structured output) after every run. The reflection ladder writes
institution_reflections later, as each window comes due.
The ladder
The runner in
learning/institution/reflect.ts
revisits each run on a fixed schedule:
| Window | Trigger | Question |
|---|---|---|
| 1d | 24h after run | Was the trigger valid? |
| 7d | 7d after run | Did the base case play out? |
| 30d | 30d after run | Was the horizon estimate right? |
| 90d / 180d / 365d | longer | Was the thesis durable? |
lazy | next time the ticker is queried | Reused as the run's Phase 0 retrospect |
Each standard window scores the run against realised price action
(price-source.ts) and, for every methodology cited in the run's role
outputs, feeds the result into methodologyStore.recordOutcome(). A
methodology graduates at its Wilson confidence edge (>= 0.55 to surface),
the same gate the confidence bumping path above
applies, so a handful of runs cannot promote an unstable rule. Lazy and
manual reflections are snapshots and do not feed the loop.
Structured methodology dedup
Free-form text is hard to dedup. "Buy BTC on RSI dip" and "Enter long when RSI oversold" are the same idea but share almost no tokens. Worse, Jaccard similarity can merge "Buy BTC at support" with "Sell BTC at support" (same tokens, opposite actions).
learning/structured-methodology.ts
solves this by forcing the judge LLM to output normalized
fields with finite vocabularies:
| Field | Allowed values |
|---|---|
direction | bullish / bearish / neutral |
primary_signal | momentum / mean_reversion / technical / fundamental / on_chain / sentiment / macro / event |
timeframe | intraday / short / medium / long |
indicators | Array of known indicators (rsi, macd, funding_rate, …) |
Dedup uses a hash of the structured fields (direction + primary_signal + timeframe + sorted indicators + asset_class).
Two methodologies with the same hash are considered duplicates
and the store increments the existing row's counters rather
than inserting a new row.
Free-text descriptions are still stored for human readability and prompt injection. The structured fields are purely a dedup key.
Similarity: Jaccard (legacy) vs TF-IDF
Before structured dedup, the fallback was text similarity. Two implementations exist:
- Jaccard 4-gram (
learning/similarity.ts) is the v1 legacy. Cheap to compute, language-agnostic, but brittle under paraphrasing and wrong on semantic inversions (the "Buy BTC / Sell BTC" trap). - TF-IDF cosine (
learning/tfidf.ts) is the preferred replacement. Word-level, stop-word aware, still language-agnostic, better at handling paraphrase.findMostSimilarTfidfis the default path the methodology store takes.
The store falls back to Jaccard only if TF-IDF fails (rare: empty corpus, weird tokenization). Both are only used when the structured dedup hash misses, which means they see far fewer calls than they did in v1.
If you're writing a new learning artifact, use
findMostSimilarTfidf directly. Do not invent a third
similarity function.
Audit subsystem
The learning loop writes plenty of per-row forensic data
(methodology_lifecycle_events, methodology_cases,
methodology_cron_runs), but those tables answer one question at a
time. The audit subsystem
(learning/methodology-audit.ts)
is the aggregate view: it reads the forensic rows, computes a
0-100 composite health score across six dimensions, and persists
one row per pass to methodology_audit_reports with structured
findings and operator-facing advisory actions.
The subsystem never mutates learning state. Its only writes are the audit report row and a heartbeat written by the learning cron itself (see Isolation invariants below).
Six scoring dimensions
Each dimension is a pure function in
learning/methodology-audit-scoring.ts.
Functions return { score: number | null, findings, advisory_actions };
a null score means "not enough data to score honestly" and gets
dropped from the composite with weight redistribution.
| Dimension | Reads | What it measures |
|---|---|---|
synthesis_quality | reflection_adjusted.reason_text parse | Penalises rapid oscillation between flag-side and recovery-side verdicts; stable runs (one-way flag or one-way recovery) score full marks. Surfaces market_stress_freeze and synthesis_auto_demote even on low-sample windows. |
graduation_fp_rate | graduated → demoted/requantized_by_judge follow-up within 30 d | Wilson lower bound on the FP rate. Graduations younger than the post-graduation observation window that have not already reversed are excluded from both numerator and denominator, so a burst of fresh graduations cannot inflate the score. |
attribution_integrity | methodology_cases.outcome_state in window | (0.7 × resolve_rate + 0.3 × (1 − backlog_share)) × 100. Returns null when there are no closed cases AND no 14-day-old pending backlog (healthy fresh install, nothing to score yet). No attribution_model drift detection — the recorded model is an intentional snapshot. |
coverage_health | methodologies (graduated AND times_used ≥ 10) | Top-level group coverage per CLAUDE.md §13 Asset Class Standard (crypto / stock / index / commodity / forex). Full marks when all five groups have ≥ 3 active methodologies; deductions scale linearly below the 3-group minimum. |
quarantine_churn | methodology_lifecycle_events state-change kinds | Excludes reflection_adjusted (fires up to 4×/day legitimately at 6 h synthesis cadence). High churn = ≥ 3 state-changing events on one methodology in window. |
cron_health | methodology_cron_runs heartbeat + pending backlog | Lag vs. 2× expected interval + backlog penalty. Lag > 7 d scores 0 (loop appears dead). Empty heartbeat + non-zero pending backlog also scores 0 (loop demonstrably not draining work). |
Composite + bands
Default weights and bands:
composite = 0.22·synthesis_quality + 0.22·graduation_fp_rate + 0.22·attribution_integrity
+ 0.14·coverage_health + 0.08·quarantine_churn + 0.12·cron_health
band: ≥ 80 healthy · 60-79 watch · 40-59 degraded · < 40 alarm · disabled (off switch)null dimensions are dropped and the remaining weights renormalise
to sum to 1. The persisted report records dimension_weights_used
so an operator reading the JSON sees exactly which dimensions
contributed.
Isolation invariants
The audit reads from the four learning tables (methodologies,
methodology_lifecycle_events, methodology_cases,
methodology_case_hints) and writes to none of them. Three
guarantees stack:
- Cooperative idle scheduling. The audit cron
(
learning/methodology-audit-cron.ts) shares aBusyTracker(core/busy-tracker.ts) withAgentLoop.run(). Every tick checksinFlight > 0(skip) and idle-since (defer). The orchestrator yields between every SQL stage viayieldIfBusy, pausing the pass when a user turn arrives mid-flight. A starvation guard forces the pass after N consecutive deferred ticks so a permanently busy agent does not lose audit coverage. - Pure-function scoring boundary. The dimension scorers in
methodology-audit-scoring.tsaccept plain arrays ofMethodology/MethodologyLifecycleEvent/MethodologyCaseshapes. They never see theMemoryStorehandle, so they cannot.prepare(...).run(...)even by accident. - End-to-end table-hash invariant.
tests/e2e/methodology-audit.test.tsSHA-256-hashes each learning table before and after every audit pass and asserts byte-level equality. The check goes beyond row-count parity: anUPDATEthat touchesupdated_atwould pass a row-count check but fail the hash.
The only reverse touch point is the heartbeat row written to
methodology_cron_runs at the tail of every learning-cron tick.
Both the in-process scheduler
(learning/methodology-cron.ts)
AND the CLI cron path
(gateway/learning-cli.ts
runFullCronCli) write this row, so the audit's cron_health
dimension works under the documented system-cron deployment.
Operating the audit
The cron is opt-in. Defaults are tuned for daily passive monitoring;
flip METHODOLOGY_AUDIT_CRON_ENABLED=1 once the learning loop has
accumulated enough data to score (typically a week or two). The
full env reference is at
Environment variables → Methodology audit subsystem.
Four CLI commands cover the operator workflow:
minara learning audit run [--window-days N] # one inline pass
minara learning audit show [--latest|--pass <id>] # inspect a report
minara learning audit trend [--days N] # composite history + sparkline
minara learning audit findings [--severity high|medium|low] # drill into findingsSee CLI subcommands → audit for the full surface.
Deferred: active probes
An earlier design proposed a seventh dimension that randomly
re-runs the agent on historical "confirmed-bad" trading cases to
test whether the learning loop now produces a different decision.
That work is deferred. An honest replay needs a frozen snapshot of
the historical decision context (prices, news, sentiment, active
methodologies, tool outputs) so the new run sees the same
information the original did. Without that snapshot, asking the
agent "should you buy ETH now?" measures current judgment, not
whether learning corrected the past mistake. Two prerequisites
gate the work: (a) a snapshot table populated by case-recorder
at hint/case time, and (b) a separate ProbeAgentLoop that does
not route through createApp() so the replay shares zero state
(skill session, tool registry, hooks) with the live agent.