Role Memory
Per-role decision reflection learning (distinct from personas and general learning)
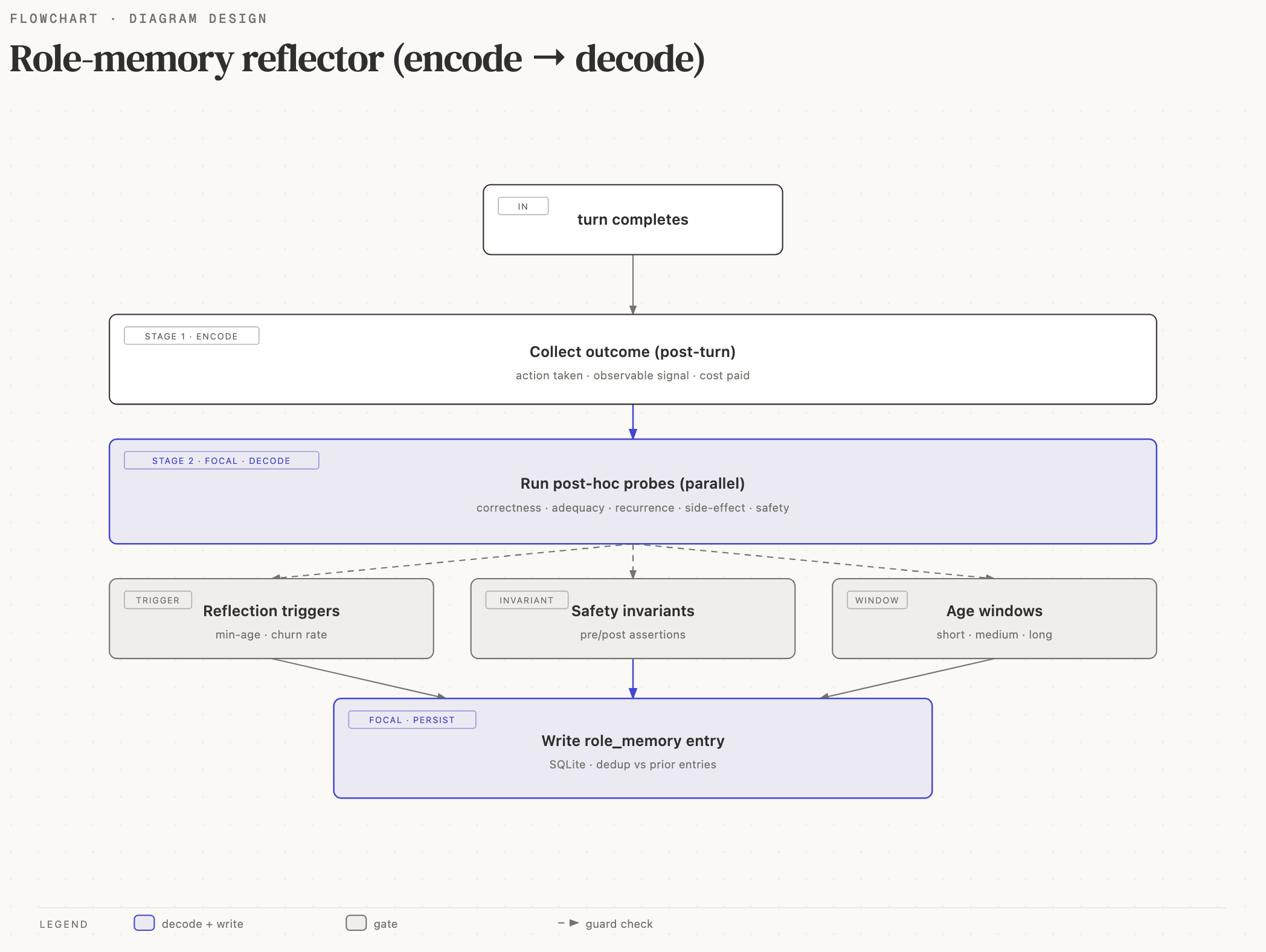
Role memory is Minara Agent's decision reflection system. When a skill makes a prediction (a trade recommendation, a valuation call, a momentum signal), role memory records it, waits for the outcome, then runs a two-stage LLM pass to classify whether the decision was right or wrong and extract an actionable lesson if it's learnable. Each lesson is scoped to a specific role that a skill declared, so you get targeted feedback rather than generic noise.
Role vs. Skill — why split them? A skill is a capability bundle (prompt + tools + permission tier). A role is a named decision context inside a skill. One skill can declare multiple roles, each with its own outcome signal and reflection prompt. Example:
analysis.valuationmight owntarget_price(checked by price-delta after 7 days) andpeer_comp(checked by relative performance vs. named peers after 30 days). Without roles, every lesson gets lumped under a single skill and becomes noise. With roles, you learn which kind of call the skill gets right and which kind it doesn't — a much more actionable signal.
See this in use: Features → Self-Improving is the user-facing side of the reflection loop. It shows how a trade recommendation turns into a lesson the agent applies next time.
Three things to disambiguate up front. Role memory is NOT:
- Persona files (SOUL.md / AGENTS.md / IDENTITY.md from Workspace Files). Those are hand-edited identity configuration. Role memory is runtime learning.
- Personalization (financial_profile + user_tags from Personalization). That's inferred user profile. Role memory is about the agent's decisions, unrelated to the user's profile.
- The general learning loop (Learning System's
review-engine/skill-manager/evaluation-loop). That one records successful procedures. Role memory runs parallel to it and recovers lessons from decisions with measurable outcomes (e.g. the price moved after your recommendation).
Files:
apps/agent/src/memory/role-registry.tsapps/agent/src/memory/role-reflector.tsapps/agent/src/memory/posthoc-probes.tsapps/agent/src/skills/types.ts: theRoleDefinition/ReflectionPolicy/OutcomeProbe/PostHocProbeinterfaces.
The four concepts
Role. A named decision context a skill owns. A skill can
declare multiple roles. Example: analysis.valuation might own
roles like analysis.valuation.target_price and
analysis.valuation.peer_comp. Each role has its own failure
modes, its own reflection prompt, and its own outcome signal.
Role memory entry. One row written every time a role makes
a decision. Stores the inputs, the decision text, the
timestamp, and an initially null reflection slot. Lives in the
role_memory table.
Outcome probe. The thing that answers "was the decision right or wrong?" Three kinds:
price_delta: measure price change of a named asset over a window (the most common probe for trading roles).custom: user-defined probe id, hooked up through the probe registry.manual: outcome is never automatic, a human reviews and marks it.
Post-hoc probe. Evidence collected after the fact to feed the reflection LLM call. Two kinds:
refetch_source: re-runs a tool the original skill used so the reflector can check "was the answer already in the data we had at t0?"- news / onchain snapshots: external signals that may have moved the market between t0 and reflection time.
DomainSkill.memoryRoles[]
Skills declare roles in their DomainSkill export:
export const valuationSkill: DomainSkill = {
id: "analysis.valuation",
// ...
memoryRoles: [
{
id: "analysis.valuation.target_price",
label: "Target price call",
failureModes: [
"anchored to recent price",
"ignored macro headwinds",
"comp set biased toward winners",
],
reflectionPrompt: `
You previously issued a target price for {asset}.
Window: {window}.
Actual outcome: {pnl}.
Evidence collected post-hoc: {evidence}.
The Stage 1 classifier tagged this as {type}.
Produce one actionable lesson ≤2 sentences.
`,
reflectionPolicy: {
outcomeProbe: { kind: "price_delta", assetField: "asset", windowHours: 168 },
minAgeHours: 168, // wait at least a week before judging
maxAgeHours: 720, // stop after 30 days
triggers: ["cron", "on_price_fetch"],
cronExpr: "0 6 * * *",
postHocProbes: [
{ kind: "refetch_source", tool: "get_price", paramMapper: "asset→symbol" },
],
},
},
],
};Every field is load-bearing:
idis globally unique. Convention:<skill_id>for single-role skills,<skill_id>.<variant>for multi-role.failureModesanchors the reflection prompt. The LLM reads them so its lessons stay grounded in realistic error categories.reflectionPromptis a template with{decision},{window},{pnl},{evidence},{type}placeholders. The reflector substitutes at reflection time.reflectionPolicy.minAgeHoursprevents judging a call before its window has fully elapsed.reflectionPolicy.maxAgeHoursprevents zombie rows from hanging around forever. Older entries are markedskippedand never reflected.triggerscontrols when reflection fires.cronruns on the declaredcronExpr.on_new_writefires as soon as a new role memory entry is written (useful for roles whose outcome is immediately measurable).on_price_fetchfires when an unrelated tool call already fetched the relevant price; it piggybacks on an existing round trip to avoid a second fetch.
The role registry
RoleRegistry.fromSkillRegistry()
runs after every skill is registered. It walks every skill's
memoryRoles[] and indexes them by id and by owning skill.
Duplicate ids across skills cause a hard boot-time error, so
you can't accidentally shadow another skill's role with a
rename.
Roles are not stored in SQLite. They live only in skill source files. Deleting a skill that declared a role stops new writes to that role; existing rows stay for audit but are no longer surfaced by the registry or the reflector.
The registry is the single source of truth for:
- Which role ids exist (drives the REPL
/reflectand/recallpickers). - The
ReflectionPolicy+ prompt template for each role. - The skill that owns a role (for prompt-builder auto-injection of recent lessons back into that skill's prompt fragment).
The role reflector
RoleMemoryReflector
is the engine. For each pending role_memory entry past its
minAgeHours:
The diagram at the top of this page shows the full flow. The steps in detail:
Stage 1: classification
Shared across every role. The prompt is a single module-level constant because classification is domain-general. Four categories:
logic_error: the decision was wrong and the error is inside the agent's reasoning. Trainable.missing_data: the decision was wrong because the agent didn't have evidence it should have fetched. Trainable.exogenous: the decision was wrong because of something the agent couldn't reasonably have known (news break, news leak, policy change). Not trainable. Store the narrative but don't produce a lesson.variance: the decision was within the noise band; can't distinguish skill from luck. Not trainable.
Only logic_error and missing_data go to Stage 2.
Stage 2: actionable lesson
Role-specific. The skill owns the prompt template. The
reflector substitutes {decision} / {window} / {pnl} /
{evidence} / {type} and calls the LLM. Output is a short
lesson that gets stored on the role memory entry.
Why Stage 2 is optional: exogenous / variance decisions
look similar to bad ones from the outside but don't admit
actionable fixes. Forcing the LLM to produce a lesson anyway
generates noise at best, hallucinated guidance at worst. Better
to log the narrative and move on.
Serial locks and triggers
When on_new_write or on_price_fetch fires, multiple code
paths may race to reflect on the same role memory entry. The
reflector holds a per-role serial lock to prevent duplicate
LLM calls. If the lock is held, the second caller drops the
request and lets the in-flight one finish.
This is specifically per-role, distinct from per-entry. A
analysis.valuation.target_price reflection can run in
parallel with a market.spot.momentum reflection; they use
different locks. But two calls into analysis.valuation.target_price
at the same time will serialize.
How role memory interacts with the general learning loop
Both systems run after the agent loop completes a turn. The two answer different questions:
review-enginecaptures "how did I successfully accomplish this task" as a replayabletool_sequence. It fires at the end of any non-trivial successful turn.- Role memory captures "was this specific decision right or wrong, and why". It fires on a schedule or when the outcome becomes measurable, often hours or days after the decision.
Both write to SQLite. Both feed prompt content back into the agent. Neither can bypass the L3 risk gate or the permission tier hook.
Adding a role to a skill
- Extend your skill's
DomainSkillexport with amemoryRoles[]array. - Pick an
OutcomeProbethat matches what "right" means for your role.price_deltais the default for trading roles; usecustomif you need a domain-specific signal (whale followthrough, on-chain settlement, etc.) and register the probe inapps/agent/src/memory/posthoc-probes.ts. - Write a
reflectionPromptthat names your role's failure modes explicitly. Generic prompts produce generic lessons. - Set
minAgeHours/maxAgeHoursbased on how long the outcome takes to mature. Intraday roles might use 4 / 48; swing roles might use 168 / 720. - Pick
triggers:cronif the reflection schedule is predictable.on_new_writeif a new write invalidates old pending entries (rare; useful for position reversals).on_price_fetchif an unrelated tool call already hits the right price endpoint; piggyback on it.
- Write a unit test that creates a role memory entry, fakes the outcome, and asserts the reflector runs Stage 1 + Stage 2.
Reference implementation: grep memoryRoles across
apps/agent/src/skills/builtin/ for existing roles to crib from.
The /reflect and /recall REPL commands
From inside the REPL:
/reflect <role>manually fires reflection for a specific role's pending entries. Useful for debugging a role's prompt template without waiting for the cron trigger./recall <role>prints the most recent lessons for a role so you can eyeball whether the reflector is producing useful output.
Safety properties
- Role memory cannot trigger fund-moving tool calls. The reflector is a pure classifier + LLM pass. It writes to SQLite and nothing else. A bad lesson cannot become a bad trade without going through the full permission tier hook.
exogenous/varianceclassifications produce no lesson. The agent never learns "whatever happened, make a new rule about it". Only decisions with clear error signatures produce guidance.- Duplicate reflection is impossible. Per-role serial locks prevent two reflector calls from updating the same entry at once.
- Budget gated. Every reflector LLM call goes through the
learningcategory of the budget tracker (see Learning System). A runaway reflector can't drain your daily budget without trippingBudgetExceededErrorfirst.
What NOT to use role memory for
- Short-term conversation state. That's the
sessionstable. - User preferences. That's either ordinary
memory_writeor Personalization. - Procedural lessons. "When the user asks X, do Y" belongs
in
review-engine/skill-managerrather than role memory. - Persona configuration. Edit SOUL.md / AGENTS.md instead. See Workspace Files.