Scenario Classifier
L0.5 intent classification that injects procedural playbooks and preloads skills
Scenarios are Minara Agent's intent layer. Before the main agent turn runs, a fast classifier maps the user's message to one or more named scenarios.
Why this layer exists: every user query has an implicit "how should this be investigated" structure. Without scenarios, the LLM has to re-derive that structure each turn (expensive + noisy). With scenarios, a deterministic keyword match + cheap LLM fallback pre-computes the investigation plan once and caches it for repeat queries.
Each matched scenario injects a procedural playbook into the system prompt and preloads the skills its playbook needs. This is how the agent turns "should I long BTC with 5x leverage" into "activate market analysis + speculation + finance-safety skills and follow the trading-strategy playbook" before the first LLM call.
Scenarios sit between skills and the agent loop:
- Skills are capabilities (which tools + what domain knowledge).
- Scenarios are flows (how to approach this kind of question).
- Agent loop is the execution engine.
Scenario files live under
apps/agent/src/skills/scenarios/ with
one defs/<id>.ts per scenario.
Why a scenario layer
Without scenarios, the agent has to discover at runtime which
skills are relevant and which order to call them in. Good for
open-ended questions, slow for common patterns. Scenarios
short-circuit the common patterns: if the user says "analyze
$BTC" the classifier knows to preload market.spot,
analysis.valuation, and research.onchain.glassnode before
the first LLM call, so the model doesn't need to spend a turn
figuring out what to activate.
Two other things scenarios buy you:
- Procedural playbooks. Each scenario has a
metaPlan+ ananalyzeblock that tells the agent the right order to gather evidence and synthesize an answer. These are merged into a single dynamic "Active Scenario Playbooks" prompt block injected after the skill fragments. - Cheap, deterministic routing. The fast keyword path runs in sub-100ms and never calls an LLM. For clear intents this is the whole classifier. The LLM fallback only fires on ambiguous messages.
Every activated scenario still goes through the existing L3
risk gate. Scenarios cannot elevate a turn's permissions. A
trading playbook preload that requires a
requires_user_confirmation skill still produces
pending_confirmation, the same as any other activation.
Classifier modes
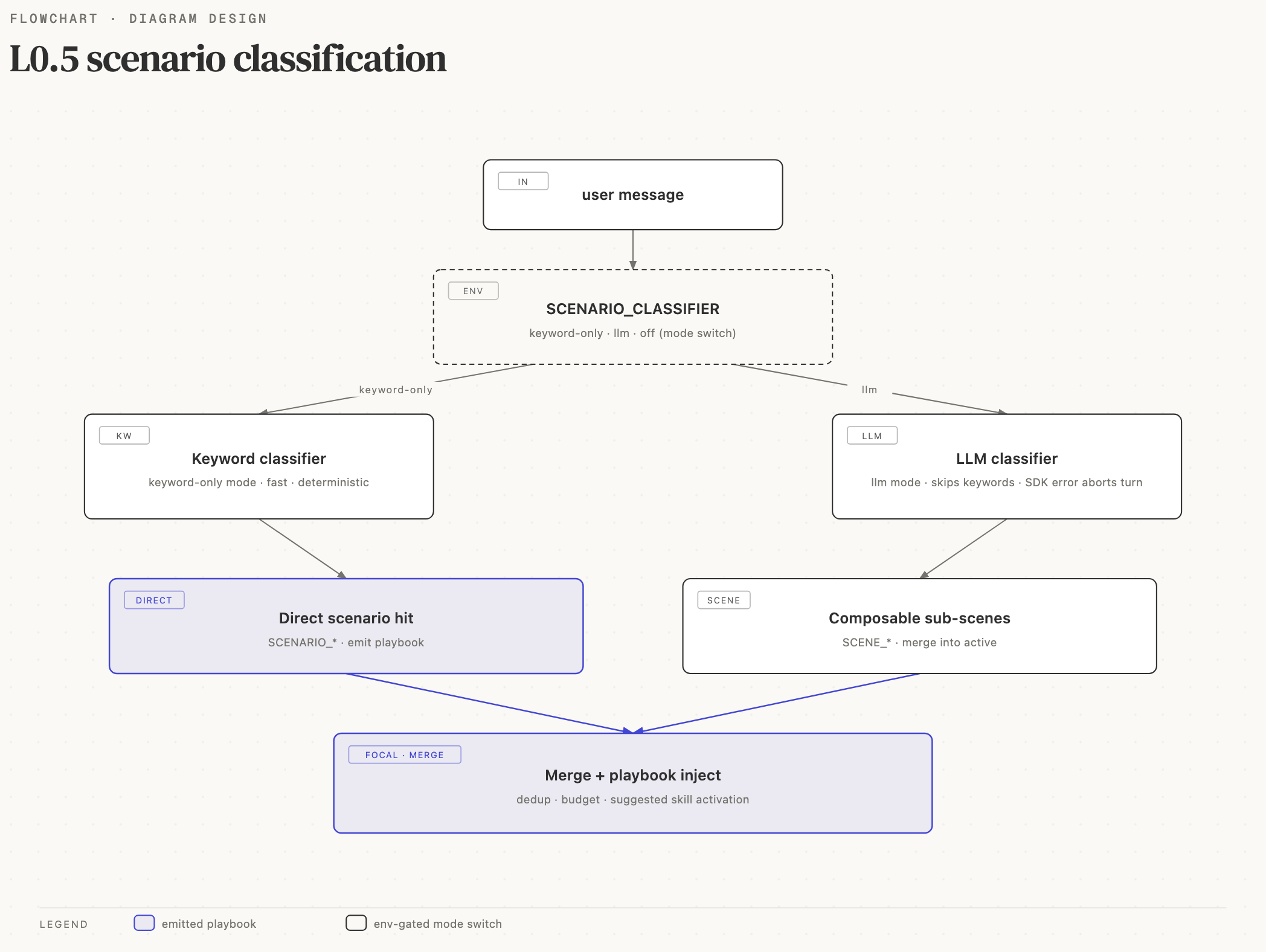
Each turn picks one classifier implementation based on
SCENARIO_CLASSIFIER. The two implementations never run together
— there is no fallback path between them.
The keyword classifier is pure string matching. Every scenario declares a bilingual (EN + ZH) keyword list, and the classifier unions the hits across scenarios. A message can activate multiple scenarios at once; they compose. Free, deterministic, no LLM call.
The LLM classifier is a cheap LLM call using the same
provider/model as the main agent loop (no secondary provider). It
sees the full scenario catalog plus the bilingual few-shot examples
and returns a JSON list of matched ids. Soft cases (empty array,
malformed JSON, all-unknown ids) degrade silently to
SCENARIO_DEFAULT; SDK-level call failures (network, auth,
rate-limit, timeout) abort the turn and surface a bilingual error
to the user instead of silently degrading.
Three modes
Controlled by SCENARIO_CLASSIFIER:
| Mode | Behavior |
|---|---|
keyword-only | Layer A only. Free and deterministic. Misses on messages with no obvious words land on SCENARIO_DEFAULT. |
llm | Layer B (LLM) only. Bypasses the keyword layer; one LLM classification call per fresh turn (cached across consecutive on-topic turns). LLM-call failures abort the turn and surface a bilingual error to the user. |
off | Classifier disabled entirely. Every turn resolves to SCENARIO_DEFAULT. |
Use keyword-only in production unless you have a specific
reason to pay for per-turn LLM classification. Use llm during
development when you want to exercise the LLM-routed path or
debug few-shot examples. Use off to isolate bugs ("does
disabling the scenario layer fix this regression").
See Environment Variables → SCENARIO_CLASSIFIER
for configuration.
Primary scenarios
Twenty-five primary scenarios. Each maps to a standalone user intent. Multiple primaries can be active at once if the user asks a compound question.
| id | description |
|---|---|
SCENARIO_DEFAULT | Fallback for queries that don't fit any other scenario |
SCENARIO_GENERAL_CHAT | General chat not about crypto, no information acquisition or analysis |
SCENARIO_MEMORY_WRITE | Explicit memory-intent only (remember, save, memorize, note this) |
SCENARIO_ACTION | Execute actions: buy / sell / swap tokens, transfer, copy-trade, trade strategy |
SCENARIO_TOKEN_ANALYSIS | Analyze a specific token / project: potential, credibility, on-chain flows |
SCENARIO_TOKEN_RECOMMENDATION | Token recommendations, hot tokens, suggestions on what crypto to buy |
SCENARIO_ASSET_ALLOCATION | Portfolio allocation, investment distribution, balancing risk and reward |
SCENARIO_HOT_MEME_COINS | Trending meme coins or meme-token recommendations |
SCENARIO_WHALE_TRACKING | Track whale / KOL / smart money activity and what influential traders are buying |
SCENARIO_MARKET_ANALYSIS | Current market conditions, outlook, crypto market analysis, overall sentiment |
SCENARIO_PRICE_PREDICTION | Predicting future price movements, long-term forecasts, crypto projections |
SCENARIO_EVENT_IMPACT | Impact of specific events on the crypto market, response strategies, news perspectives |
SCENARIO_DEFI_ANALYSIS | DeFi projects, protocol comparisons, staking, yield farming, high-APY protocols |
SCENARIO_TRADING_STRATEGY | Trading strategies, exit strategies, technical indicators, TP / SL levels |
SCENARIO_AIRDROP_OPPORTUNITY | Airdrop opportunities, airdrop analysis, airdrop tracking, notifications |
SCENARIO_PERSON_ANALYSIS | Analyzing Twitter profiles, KOLs, or influential figures in crypto |
SCENARIO_LISTING_PREDICTION | Predicting upcoming exchange listings, new token launches, TGE announcements |
SCENARIO_EVENT_PREDICTION | Predicting future events, event probabilities, prediction markets, price predictions |
SCENARIO_STOCK_ANALYSIS | Analyze specific stocks / companies, evaluate investment potential and credibility |
SCENARIO_VISUALIZATION | Visualizing data, creating charts or spreadsheets |
SCENARIO_CHART_TECHNICAL_ANALYSIS | Analyze K-line / price-trend charts (uploaded images); TA and trading advice |
SCENARIO_NEWS_VERIFICATION | Verify tweets / news screenshots: authenticity and market impact |
SCENARIO_PROFILE_VERIFICATION | Verify Twitter profile screenshots: authenticity and scam risk |
SCENARIO_WHITEPAPER_ANALYSIS | Analyze project whitepapers (PDF), evaluate project quality and investment value |
SCENARIO_TRADING_RECORD_ANALYSIS | Analyze user trading records (CSV / Excel upload or wallet history); personalized profile |
Composable sub-scenarios
Eight SCENE_* sub-scenarios cover equity-style valuation
flavors. They attach to a primary (usually STOCK_ANALYSIS or
TOKEN_ANALYSIS) to inject an additional playbook targeted at
a specific asset shape.
| id | description |
|---|---|
SCENE_STOCKS_VALUATION | Listed stocks (US / global / ADR): single-name valuation, growth, multiples, peer comparison |
SCENE_CRYPTO_TOKENS_VALUATION | Crypto tokens / DeFi protocols: fee capture, user activity, P / protocol revenue |
SCENE_CRYPTO_EQUITIES_VALUATION | Crypto-related listed companies (exchanges, miners, infra): equity multiples + crypto beta |
SCENE_CRYPTO_TREASURY_VALUATION | Companies with large crypto treasuries (MSTR): NAV / mNAV, premium / discount, leverage reflexivity |
SCENE_TOKENIZED_STOCKS_VALUATION | Tokenized stocks / synthetic wrappers: peg, redemption, premium / discount, liquidity |
SCENE_DERIVATIVES_POSITIONING | Options / futures on stocks and crypto: positioning, skew, max pain, expiry |
SCENE_ETF_INDEX_VALUATION | ETFs and indices: composition, sector weights, aggregate valuation, macro sensitivity |
SCENE_INDUSTRY_MACRO_CYCLE_VALUATION | Industry sectors, macro cycles, country-level markets: inflation, rates, commodities, policy |
When a primary like SCENARIO_TOKEN_ANALYSIS activates, the
classifier also checks whether any SCENE_* keywords match. A
query like "analyze MSTR" activates
SCENARIO_STOCK_ANALYSIS + SCENE_CRYPTO_TREASURY_VALUATION
so the agent gets both the general stock analysis playbook and
the NAV / mNAV specific guidance.
The Scenario interface
Each scenario file exports a Scenario with this shape (see
apps/agent/src/skills/scenarios/types.ts):
interface Scenario {
id: string; // SCENARIO_TOKEN_ANALYSIS
description: string; // ≤100 char "pushy" description
keywords?: string[]; // bilingual keyword list
assetClasses?: AssetClass[]; // soft hint
lifecycleStages?: LifecycleStage[];
suggestedSkillIds?: string[]; // skills to preload
metaPlan: string; // procedural playbook (meta layer)
analyze: string; // synthesis rules (analyze layer)
}The metaPlan + analyze strings are the procedural playbook.
They get merged into the dynamic "Active Scenario Playbook" prompt
block after the active skill fragments. The rendering is strict
by default — an imperative checklist header and a Synthesis
section gated on data-gathering completion. Revert to the
soft-advisory rendering via DISABLE_STRICT_PLAYBOOK=1. There is
no per-scenario char cap; the combined size is only bounded by
the overall KNOWLEDGE_BUDGET_TOKENS negotiator (default 15000).
Adding a new scenario
- Create the file at
apps/agent/src/skills/scenarios/defs/<id-lowercase>.tsexporting aScenarioconst. UseSCENARIO_*for primary intents,SCENE_*for composable sub-scenarios. - Register in
apps/agent/src/skills/scenarios/catalog.ts(oneimport+ one array push). Do not inline playbook text here. - Write classifier test examples in
tests/unit/skills/scenario-classifier.test.ts. At least one message that should hit the new scenario and one that should not. suggestedSkillIdsmust reference real skill ids.ScenarioRegistry.validate()runs at app boot and hard-fails on any id that isn't inBUILTIN_SKILLS. Grepapps/agent/src/skills/builtin/for the literalid:field. Do not derive skill ids from filenames (see Conventions §12).- Keep playbooks focused. There is no per-scenario char cap,
but every line shows up in the system prompt on matching turns —
trim merciless when the metaPlan grows past the useful step
list, and let the
KNOWLEDGE_BUDGET_TOKENSnegotiator handle bounds. - Do not edit
classifier.ts/session.ts/registry.ts/prompt-builder.ts/agent-loop.ts/app.ts. If you feel the urge, your scenario's needs are out of band and belong in a separate framework PR.
Debugging which scenario fired
Scenario activation lands in structured logs under the
skills/scenarios category:
grep 'skills/scenarios' $dataDir/logs/*.ndjson | \
jq -r 'select(.event == "scenarios_classified") | {turn: .correlation_id, ids: .data.scenarios}'The scenarios_classified event records the turn correlation
id and the list of scenarios that fired, plus whether Layer A
or Layer B produced each one. Combined with the audit log's
turn rows you can trace every turn back to the exact classifier
decision.
If a scenario isn't firing when you expect it to:
- Confirm
SCENARIO_CLASSIFIERis not set tooff. - Check the message against the scenario's
keywordslist literally. The match is lowercased substring. - If no keyword hit, switch to
llmmode and see whether the LLM classifier picks it up. If it does, your keyword list has a gap; add the missing term. - Check the structured log for
scenario_validate_error. A typo insuggestedSkillIdswill mask the scenario silently in CI but hard-fail at boot.
Safety properties
- Scenarios cannot bypass the L3 risk gate. A scenario that
preloads
minara.autopilot(arequires_user_confirmationskill) still producespending_confirmationfor user turns. Only operator-authored workflows with explicitskill_scopeand thetrustedSeedflag can preload high- risk skills without confirmation. See Workflows. - Scenarios are deterministic in
keyword-onlymode. Same input produces the same classification. This is by design and is what makes the fast path cheap. - Classifier failures fall back to
SCENARIO_DEFAULT. A Layer B LLM call that fails or times out does not crash the turn; the router just usesDEFAULTand the agent continues.
See this in use
- Features → Market Analysis — how
SCENARIO_TOKEN_ANALYSIS/SCENARIO_MARKET_ANALYSISshape what the agent answers with. - Contributing → Adding a Scenario — the scenario-author contract.
- Internal deep-dive:
apps/agent/docs-src/scenarios.md(repo-internal doc with classifier pseudocode, Phase-2 learning pipeline, and the full 33-scenario registry).